Pipeline Architecture Style
Also known as the pipes and filters architecture. As soon as developers and architects decided to split functionality into discrete parts, this pattern followed. Most developers know this architecture as this underlying principle behind Unix terminal shell languages, such as Bash and Zsh.
Developers in many functional programming languages will see parallels between language constructs and elements of this architecture. In fact, many tools that utilize the MapReduce programming model follow this basic topology.
Topology
The pipeline architecture style comprises two fundamental components: pipes and filters, each playing a specific role in the communication flow. The unidirectional nature of pipes and filters within the pipeline architecture promotes a design that fosters compositional reuse. Many developers have discovered this ability using shells.
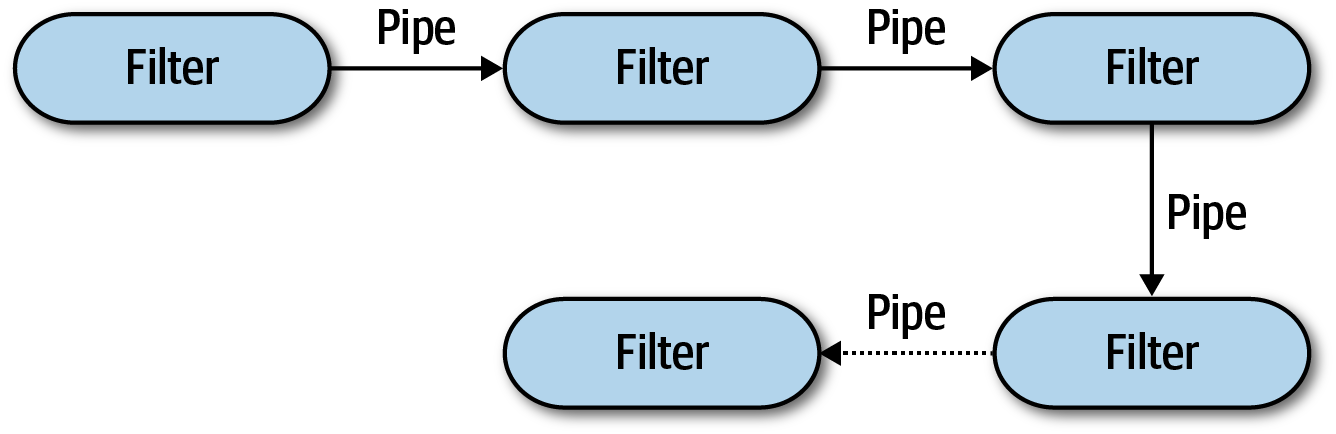
Basic topology for pipeline architecture from Fundamentals of Software Architecture.
Pipes
Pipes works as communication channels connecting the filters. Typically, each pipe is unidirectional and establishes a point-to-point communication rather than broadcast, prioritizing performance. It accepts input from a singular source and always directs the output to another. While the data format can vary, architects often favor smaller data packets to ensure high performance within the pipeline.
Filters
Filters operate as self-contained entities, independent of other filters, and generally remain stateless. It is crucial for each filter to be dedicated to a specific task. Complex tasks should be managed through a sequence of filters rather than a single one.
The pipeline architecture style involves four types of filters:
Producer
Serves as the initial stage of the process, focusing on outbound operations only, and is sometimes referred to as the source.
Transformer
Accepts input, possibly conducts transformations on some or all of the data, and then directs it to the outbound pipe. This function is comparable to the map feature in functional programming.
Tester
Accepts input, verifies one or more criteria, and optionally generates output based on the test. This bears similarity to the reduce operation in functional programming.
Consumer
Represents the end point for the pipeline flow. Consumers often persist the final results of the pipeline process to a database or display the outcomes on a user interface screen.
Example
The pipeline architecture pattern is prevalent in various applications, particularly those involved in straightforward, one-way processing. ETL tools (extract, transform, and load) also leverage this architecture for efficient data flow and modification between databases or data sources.
To exemplify the practical application of the pipeline architecture, consider the following scenario: service telemetry information is streamed from multiple services to Apache Kafka. Observe the utilization of the pipeline architecture style to handle diverse data types streamed to Kafka.
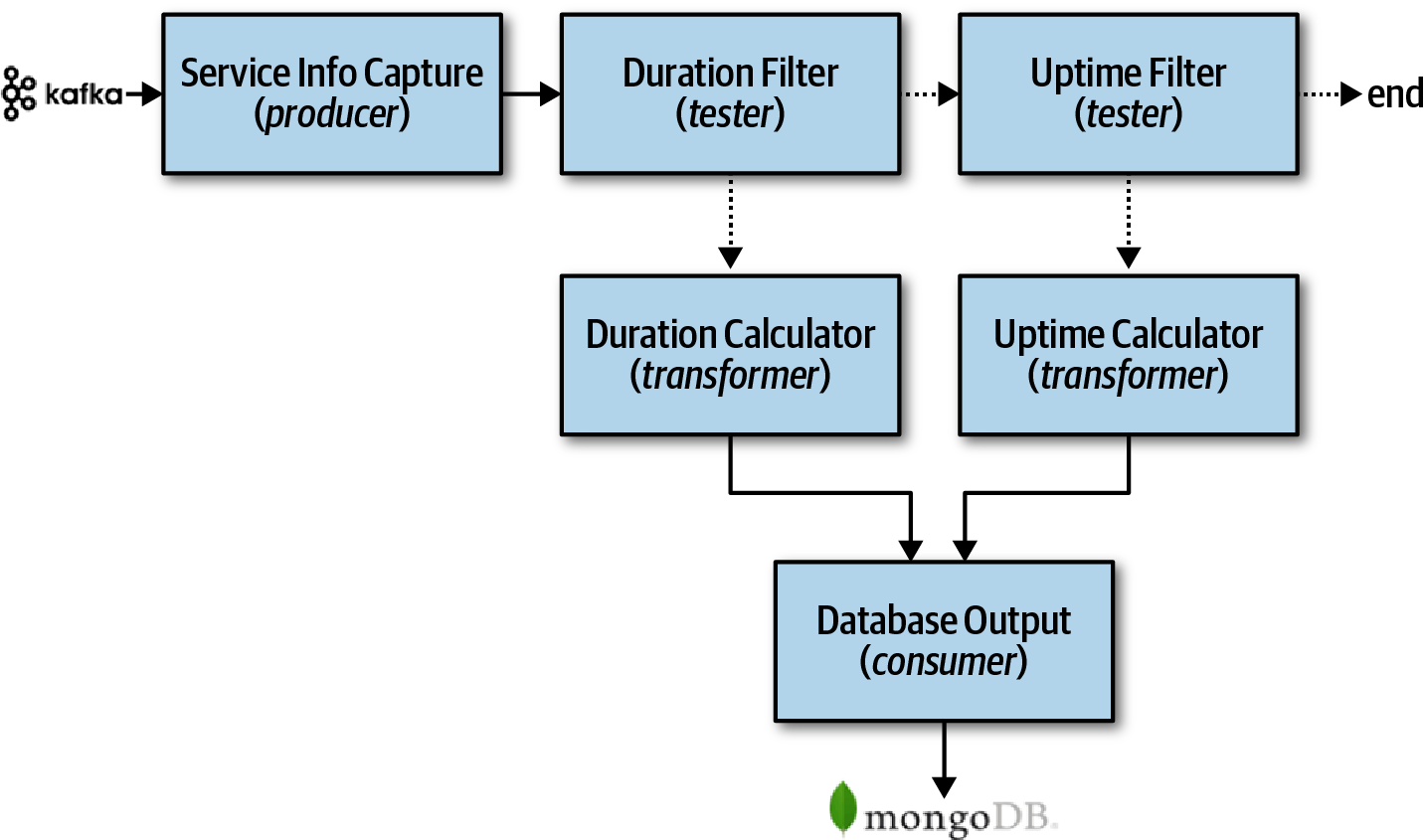
Pipeline architecture example from Fundamentals of Software Architecture.
Service Info Capture Filter (Producer)
The Service Info Capture filter subscribes to the Kafka topic and receives service information. It then forwards this data to the Duration Filter. This filter focuses solely on establishing a connection with a Kafka topic and receiving streaming data.
Duration Filter (Tester)
The Duration Filter checks if the data is about the service request duration. If it is, the data goes to the Duration Calculator, and if not, it's sent to the Uptime Filter.
Uptime Filter (Tester)
The Uptime Filter verifies if the data is about uptime metrics. If it's not, the pipeline ends. If it is, the data goes to the Uptime Calculator.
Duration and Uptime Calculator (Transformer)
The Duration Calculator and Uptime Calculator transmit the modified data by them to the Database Output consumer
Database Output (Consumer)
Stores the data in a MongoDB database.